処理に費やす手数
直接選択法では、値の並び方によっては処理に大きな手間がかかります。一方、二分探索木では、処理の手間が大きく軽減されます。しかし、どのようなときでも二分探索木の法が効率的であるとは限りません。処理にかかる手間について考えてみましょう。
わずかな差が大きな差となる
ランダムに並んだ値から1つの値を見付ける場合、第51回で紹介した先頭から順に比較していく直接選択法に比べて、二分探索木では処理の手数が大きく変わってきます。
例では比較対象の値が少ないため、処理の『速さ』が問題になることはありません。しかし、比較対象が数千~数万個になってくれば、処理にかかるわずかな手数の差が、大きな時間差となってしまいます。
手数が少ないほど速い
直接選択法では、運がよければ探索値は被探索値群の先頭にあり、1回の比較で値が見付かります。その半面、運が悪ければ被探索値は被探索値群最後尾に位置しており、被探索値の件数だけ比較を繰り返さなければなりません。
被探索値群の件数をnとすれば
最小:1回
最大:n回
の手数がかかることになります。
この、処理にかかる手数のことをオーダー(order)と言います。オーダーは小さければ小さいほど効率的だと言えますですが、常に最小のオーダーで済むような手順はあり得ません。同様に、常に最大のオーダーとなる手順もありません。被探索値群の並び方によって、オーダーは変化するためです。
したがって、オーダーの最大と最小との差が最も小さくなる手順が、最も効率的であると言えます。
木構造の形でオーダーが変わる
二分探索木もまた、かかる手数は直接選択法と同じく
最小:1回
最大:n回
です。
さらにその構造を構築する必要があるため、直接選択法に比べて前処理に手間がかかります。しかし、被探索値が膨大な件数になれば、前処理のために費やす手数はさほど大きな問題とはならなくなります。
むしろ、前処理に手間をかけても、その後の探索で先頭ノードを比較した途端に、被探索値群の件数が一気に減少することのメリットの方が大きいのです。二分探索木では、場合によっては2回目以降のノードの数が1/2以下になることがあります。
手数は先頭の値次第
では、二分探索木がどのようなときでも効率がよいのかと言えば、そういう訳でもありません。二分探索木にも欠点があります。
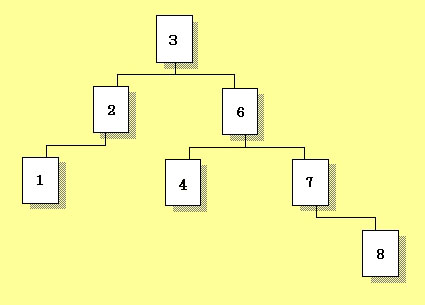
被探索値が、今回の例のように
3, 6, 2, 7, 1, 4, 8
と並んでいた場合、先頭の値である3は1~8の数値のほぼ中間値です。そのため探索木は先頭のノードからほぼ左右均等に枝がぶら下がることになります(図2)。
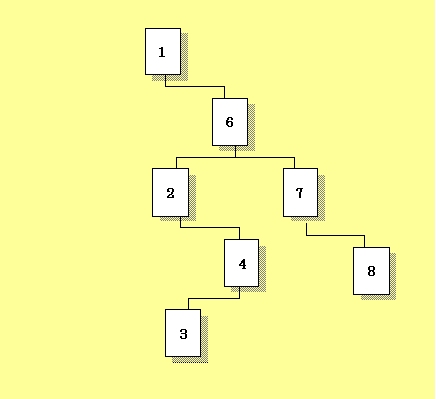
しかし、先頭の値が最小値の1であれば、続く値はすべてそれより大きくなるためノードはすべて右に偏り、処理の手間は直接選択法と変わらなくなります(図3)。先頭の値が最大値の8で遭った場合は、逆にノードが左に偏り、やはり処理の手間は直接選択法と変わらなくなります。
先頭が中間値のときが最も効率的
つまり。二分探索木による探索では、先頭のノードが保持する値が被探索値群の中間値付近である場合に最も効率がよくなり、そうでなかった場合には効率が悪くなる――という傾向があります。
二分探索木で効率的な探索を行うためには、先頭のノードを全体の中間値付近にする必要があります。そのためには、被探索値群から中間値を探し出してそれを先頭のノードにする――という前処理が必要になります。
そのためには、被探索値群の値をすべて調べ、そこから中間値を見付けなければなりません。この処理にかかる手間は、一般に直接選択法で先頭から値を比較していく手間と大きく変わりません。
ならば、直接選択法と二分探索木との効率の差は『運次第』ということになってしまいます。しかし、唯一両者の効率の差が明らかになる場合があります。それは、被探索値群の最大値と最小値が明確である場合です。アンケートの集計のようにサンプル(調査対象)の数が分かっていれば、最小値は0で最大値はサンプル数です。そのような場合には、最大値であるサンプル数の1/2の値を中間値とし、それを先頭のノードに持ってくれば、二分探索木は(おそらく)左右ほぼ均等に近い形となるはずです。
但しこれも、アンケートの結果があくまで理想的な分布となっている場合が前提なので、やはり『運次第』という側面は拭えません。設問の立て方にもよりますが、アンケートの結果から特定の値を探す場合には、二分探索木は効率的な仕組みであると言えます。
*
たくさんの値の中から1つの値を見付けるための手順として、直接選択法と二分探索木を紹介してきました。
効率的な処理のためには処理の手順に工夫を凝らす必要があり、そのためにはデータ構造を工夫する必要があります。処理手順――アルゴリズムを考えるということは、実はデータ構造を工夫することでもあります。手順だけでもデータ構造だけでも、効率的な処理は実現できません。
次回は、さらに効率的な探索のための処理を考えていきましょう。
|
|
|