第33回
データ構造(12)~構造体の利用例と共用体
共用体構造体と似たデータ構造に共用体があります。構造体が型の異なる複数の変数を1つにまとめるのに対して、共用体は一定の範囲のメモリ領域を複数の異なる型で共有します。共用体の定義~union共用体指定子共用体はunion命令で定義します。基本的な定義方法は構造体と同じです。union命令は「共用体指定子」とも呼ばれます。union <タグ> {
<変数宣言>
:
};
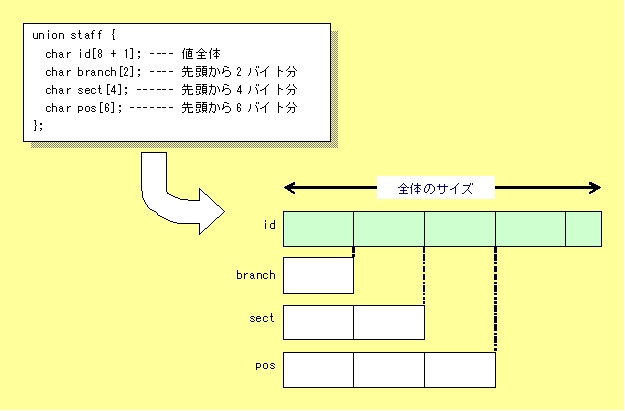
共用体では、最初に宣言したメンバのサイズが全体のサイズとなります。それ以降に宣言されたメンバは、最初に宣言したメンバの一部(先頭から宣言された変数の占有するサイズ分)を示します。 従って、2番目以降のメンバのサイズは最初に宣言したメンバより小さくなければなりません。 全体と部分を1つにまとめる社員の識別番号(社員ID)が、以下のようなルールで定められているとします。それぞれのIDは2桁のchar型配列(文字列)で構成されています。支社ID 部ID 役職ID 個人ID たとえば、大阪支社の総務部人事係長のAさんの識別番号が以下のようになっていたとします。 支社ID 部ID 役職ID 個人ID 02 05 06 18 Aさんの識別番号はこれらをつなげた「02050618」です。この番号から、Aさんが何支社に属するかは先頭の2文字、何支社の何部に属するかは先頭の4文字、さらに役職は先頭の6文字を見れば分かります。 そのような場合に、識別番号を共用体で定義すれば以下のようになります。 union staff {
char id[8 + 1]; ---- 値全体
char branch[2]; ---- 先頭から2バイト分
char sect[4]; ------ 先頭から4バイト分
char pos[6]; ------- 先頭から6バイト分
};
構造体は、構成要素(メンバ)である変数をそれぞれ異なるデータとしてそれらをつなげた形になりますが、共用体は 先頭のメンバのサイズが全体のサイズで 以下に続くメンバは 全体を先頭から部分的に切り出したものとなります。 共用体の定義共用体の定義と共用体型変数の宣言は構造体と同じで、通常はtypedef命令を使い、タグを省略します。typedef union {
char id[8 + 1]; ---- 値全体
char branch[2]; ---- 先頭から2バイト分
char sect[4]; ------ 先頭から4バイト分
char pos[6]; ------- 先頭から6バイト分
} _staff;
最後の“_staff”が共用体に付けられた別名です。これで、_staff型の変数を以下のように宣言できます。 _staff stf; 共用体の利用例構造体に比べて、共用体の使われる局面は多くありません。構造体と組み合わせて、文字コードを扱う例を紹介しておきましょう。たとえば、Shift JISコードの日本語1文字を16進数のまま保持する場合、以下のような共用体と構造体の組み合わせが考えられます。 /* 8bit2個=16bitの構造体 */
typedef struct {
unsigned char lo; /* 下位8ビット */
unsigned char hi; /* 上位8ビット */
} _lohi;
/* 16bitの共用体 */
typedef union {
unsigned short int word; /* 16ビットのデータ */
_lohi sep; /* 8ビット2個の構造体 */
} _Sjis;
Shift JISコードの1文字は16ビット(2バイト)ですが、上位8ビット(16進数で先頭の2文字)と下位8ビット(16進数で後の2文字)に分けられます。そこで、共用体の中にunsigned char型(1バイト)の2つの変数(上位8ビットと下位8ビット)で構成される構造体を組み込みます。 これによって、日本語1文字を全体をunsigned short int型のメンバwordで、上位8ビットを構造体_lohi型のメンバsepのhi、下位8ビットを同じくメンバsepのloで表すことができます。 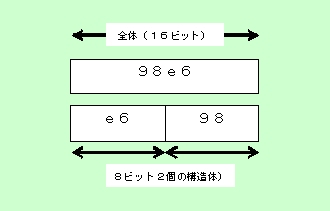 図2:日本語の1文字を保持する共用体 共用体と構造体の組み合わせ構造体を別に定義すると煩雑になるため、以下のように共用体の定義内でメンバとして構造体を定義する方が分かりやすくなるでしょう。/* 16bitの共用体 */
typedef union {
unsigned short int word;
/* 8bit2個=16bitの構造体 */
struct {
unsigned char lo;
unsigned char hi;
} lohi;
} _Sjis;
「画」という漢字はShift JISコードで「0x89E6」です。これを16進数のまま保持して、「全体のコード・上位8ビット・下位8ビット」のそれぞれの値を表示するプログラムはリスト2のようになります。 このプログラムを実行すると、以下のように表示されます。全体が89e6で上位が89、下位がe6──となっています。 C:¥CLANG>exe¥ex3301 16bit : 89e6, 8bit high : 0089, 8bit low : 00e6 Shift JISコードでは、上位8ビットに1バイト文字(半角の英数記号)を表すASCIIコードには存在しない値が割り当てられています。従って、ワープロやエディタなどで日本語を扱う場合、上位8ビットを調べることでそれが1バイト文字なのか2バイト文字(日本語)なのかを判別できます。 リスト2:文字「画」の文字コードを16進数で表示するプログラム(ex3301.c) #include <stdio.h>
/* 16bitの共用体 */
typedef union {
unsigned short int word;
/* 8bit2個=16bitの構造体 */
struct {
unsigned char lo;
unsigned char hi;
} lohi;
} _Sjis;
int main(void)
{
_Sjis jpcode;
/* 「画」の文字コードを代入 */
jpcode.word = 0x89e6;
printf("16bit : %04x, 8bit high : %04x, 8bit low : %04x\n",
jpcode.word, jpcode.lohi.hi, jpcode.lohi.lo);
return (0);
}
|
Copyright © MESCIUS inc.