上位バイトと下位バイトの逆転について
リスト2を見て「?」と思った人がいるかもしれません。共用体内の構造体lohiでは、下位を示すloが先で上位を示すhiが後に定義されています。16ビットのコード全体を表すwordでは左が上位桁、右が下位桁となっているのに、なぜでしょう?
表記と格納方法の違い
共用体内の構造体lohiの定義を、もう一度見てみましょう。
struct {
unsigned char lo;
unsigned char hi;
} lohi;
下位8ビットを示すメンバ“lo”が先に、上位8ビットを示すメンバ“hi”が後に定義されています。全体を表す16bitの“word”では“89e6”となっているのに、構造体では下位のe6が先で上位の89が後……ということです。
これは、値の表記方法とメモリ内でのデータの格納方法の違いによるものです。
逆ワード形式
数値の記述では、たとえば「1234」と表記されていれば、一番右が下位桁(1の位)で左に向かって上位桁になります(値を読み取る場合は、左の上位桁から右の下位桁に向かって「せんにひゃくさんじゅうよん」と読み進みます)。
一方コンピュータのメモリは、左が下位アドレスで右に向かって上位アドレスに進む形で表現します。メモリはバイト(8ビット)単位で値を格納するため、今回の例のように16ビット(2バイト)の値は、下位1バイトが下位アドレス(メモリの表現では左側)に、上位1バイトが上位アドレス(メモリの表現では右側)に保存されることになります。
これを人間に分かる──16ビット(2バイト)で1つの意味をなす──形で表すとき、「左が上位/右が下位」という形に変換して“89e6”のようにしています。
これはインテル系CPUの特徴で『逆ワード形式』と呼ばれます。ワード(word)とは2バイトのデータのことです。実際には、2バイト以上のデータでもメモリ上では左から右に向かって「下位→上位」の順でバイト単位に記録され、それら複数倍のデータをまとめて扱う際に順序が逆に並べ替えられます。
この形式について、一般的な高級言語のレベルでは気にかける必要はありません。しかし、アセンブリ言語やCのように1つのデータを様々な形で切り分けて扱える言語で、複数バイトのデータを扱う際には注意が必要です。
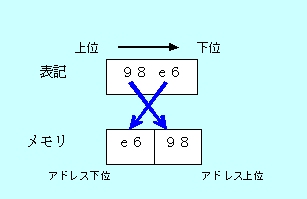 図3:2バイトデータの上位と下位はメモリ内で逆転している
|
|
|