In This Topic
TextParser library provides HTMLExtractor class for setting up and using the HTML extractor which can be used to extract specific text from any kind of HTML document which makes it an efficient and reliable tool for text extraction.
Template-Based extractor is not suitable for a complex structure like HTML and can be useful to extract small custom text format specified by the user considering a plain text source. In HTML, the structure and template source can also differ. While HTML extractor is even capable of extracting text from a mail that is not exactly similar to the template email.
It is usually observed that the emails sent by a specific provider follow a similar presentation structure. So, we can use one mail as a template to extract text from all the other emails. Using HTML extractor, we can automate the process of extracting desired text from an HTML source document. For example, extracting flights tickets, e-commerce receipts, and other information.
The text places to be extracted from the source are called place holders of the template. Following are the types of placeholders in HTML extractor:
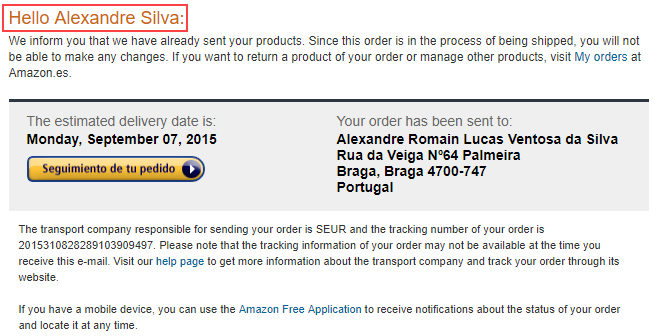
- Fixed place holders: Fixed place holders are the place holders that occur only once in the HTML document. For example, customer name and customer address in an order confirmation mail as shown below:
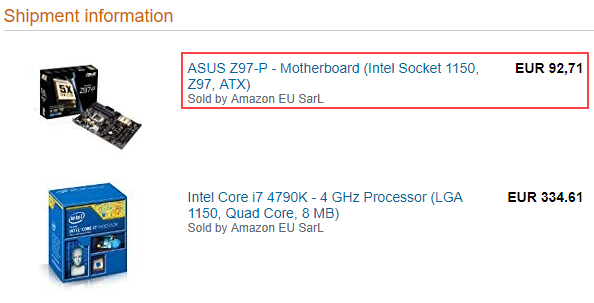
- Repeated place holders: Repeated place holders are used to extract an arbitrary number of repeated items in the HTML document. For example, the list of ordered items in an order confirmation mail as shown below:
For adding fixed and repeated placeholders to the template specification used by the HTML extractor, AddPlaceHolder method of the HTMLExtractor class is used. This method accepts the following parameters:
- The name to be used to refer to the place holder.
- The XPath of the HTML element containing the selected text from the place holder.
- You can also opt to specify the 0-based character index where the selected text begins with respect to the textContent property of the HTML element pointed by fixedPlaceHolderXPath along with the selection length (number of characters of the selected text).
- If the selection starting index and selection length are not specified, the entire value of the textContent property of the HTML element pointed by fixedPlaceHolderXPath is considered to be the selection.
Note: The only difference between adding fixed and repeated placeholders is that a name (For example, ordered articles) for the repeated structure must be provided in repeated placeholder. So, we can understand that ordered articles will consist of as many instances as the number of items in the order. Each instance will consist of a list of instances of repeated place holders (For example, article name, article price, and others) defined for ordered articles.
Key characterstics of HTML extractor
The
HTML extractor is not character oriented and uses "
notion of word" to understand the placeholder defined by the user. For the HTML extractor, a word can be of two types, a symbolic word or a literal word. A symbolic word consists a sequence of characters that are not used to express literal content such as
$ % , . < > ; ( ) { } [ ] @ # ‘ ”.
The algorithm used in the extractor enables it to extract the text correctly even if there is a difference between the source email and the template email. Let us take an example to understand it clearly.
Check Example
Consider the following HTML node that contains the total order amount in a template email:
<strong>EUR 432.09</strong>
To extract the decimal part from this node, we need to define a fixed placeholder with the selection starting index as ‘8’ and the selection length as ‘2’. The extractor algorithm follows the "notion of word" and considers the place holder described above, as starting in the fifth word (1st “EUR”, 2nd “ “, 3rd “432“, 4th “,”, 5th “09”) of the node text and consisting on the full range of the fifth word.
Now, let’s consider a possible source as:
<strong>USDOLLAR 7891,13 </strong>
With the word notion described above, “13” is extracted from the source. Similarly, if instead of “13” the decimal part is “124563”, even that will be extracted correctly, using the same place holder.
Now, Let us take an example to understand how to use the HTML extractor.
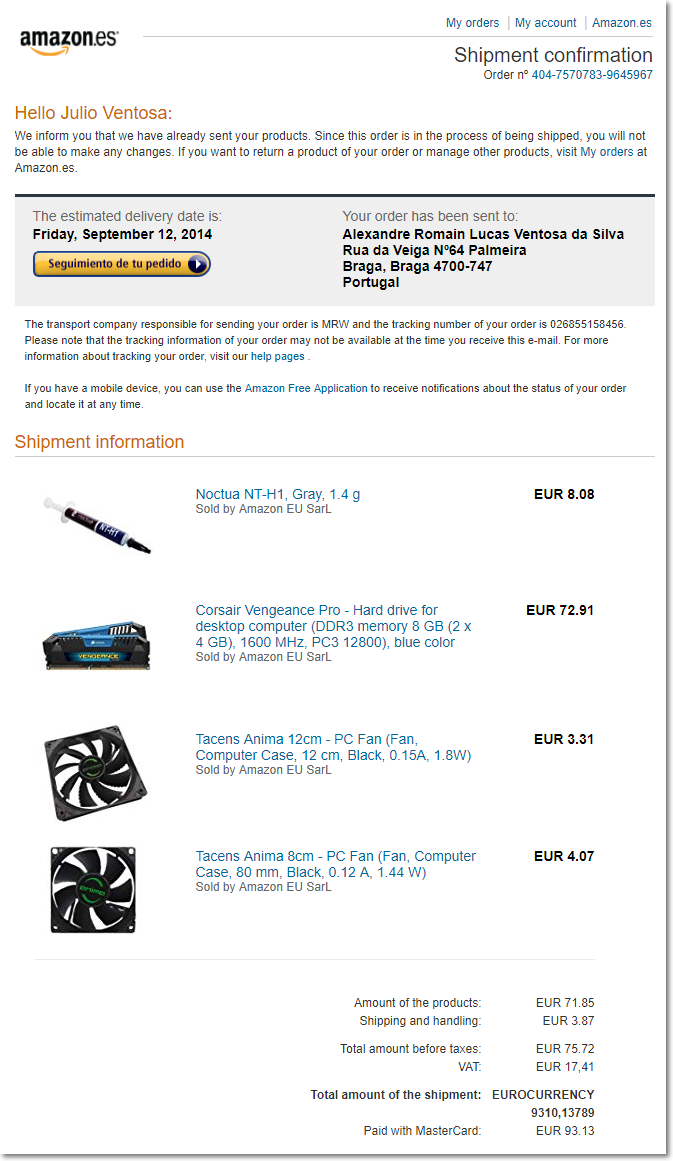
Consider the following order confirmation email from Amazon. The HTML source of this email will be used as the template for extracting information from all the other amazon order confirmation mails.
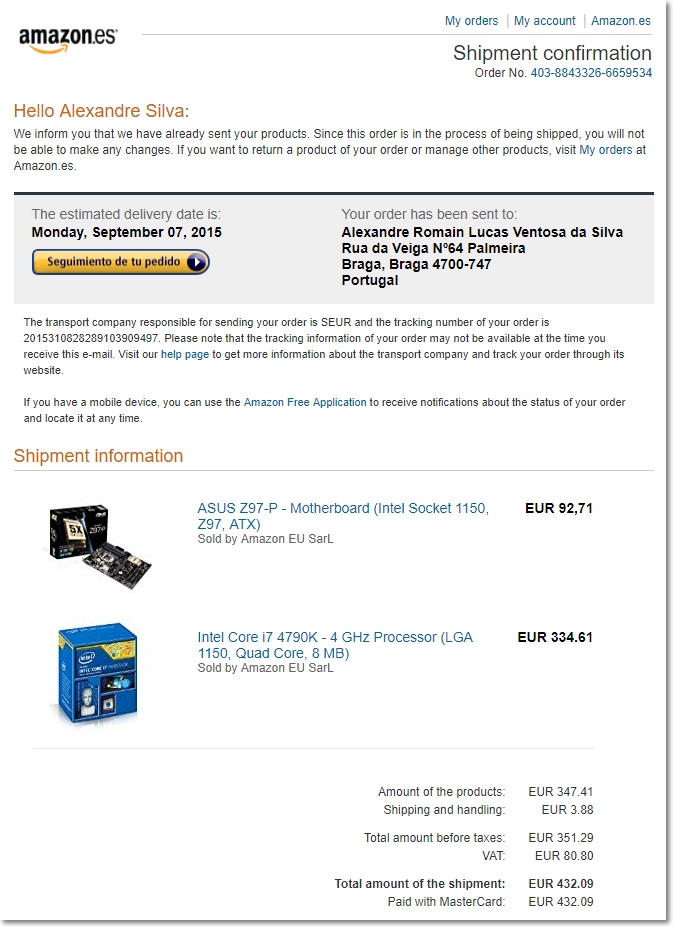
The code snippet provided below shows how you can define fixed place holders to extract the name of the customer, order delivery date and the decimal part of the total order amount.
To extract text using the HTML extractor class, you need to follow these steps:
- Open the HTML stream which will be used as the template for extracting the text from other similar emails.
Stream amazonTemplateStream = File.Open(@"amazonTemplateEmail.html", FileMode.Open);
- Create an instance of HTMLExtractor class and pass the stream containing the template as parameter to it.
HtmlExtractor htmlExtractor = new HtmlExtractor(amazonTemplateStream);
- Define the fixed placeholders using the AddPlaceHolder method. Customer name, delivery date, decimal part of the total amount
//Fixed placeHolder for the customer name
String customerNameXPath = @"/html/body/div[2]/div/div/div/table/tbody/tr[2]/td/p[1]";
htmlExtractor.AddPlaceHolder("Customer Name", customerNameXPath, 7, 15);
//Fixed placeHolder for the expected delivery date
String deliveryDateXPath = @"/ html / body / div[2] / div / div / div / table / tbody / tr[3] / td / table / tbody / tr[1] / td[1] / p / strong";
htmlExtractor.AddPlaceHolder("Delivery Date", deliveryDateXPath);
//Fixed placeHolder for the decimal part of the total amount of the order
String totalAmountXPath = @"//*[@id=""shipmentDetails""]/table/tbody/tr[8]/td[2]/strong";
htmlExtractor.AddPlaceHolder("Total order amount decimal part", totalAmountXPath, 8, 2);
- Define the repeated placeholders using the AddPlaceHolder method.
//Repeated block for each article in the order
String articleNameXPath = @"//*[@id=""shipmentDetails""]/table/tbody/tr[1]/td[2]/p/a";
htmlExtractor.AddPlaceHolder("ordered articles", "article name", articleNameXPath);
String articlePriceXPath = @"//*[@id=""shipmentDetails""]/table/tbody/tr[1]/td[3]/strong";
htmlExtractor.AddPlaceHolder("ordered articles", "article price", articlePriceXPath);
String articleSellerXPath = @"//*[@id=""shipmentDetails""]/table/tbody/tr[1]/td[2]/p/span";
htmlExtractor.AddPlaceHolder("ordered articles", "article seller", articleSellerXPath, 12, 18);
- Open the source HTML stream from which you wish to extract the text.
Stream source = File.Open(@"amazonSourceEmail.html", FileMode.Open);
- Extract the desired text from the input stream using the Extract method of the HTMLExtractor class. This method returns an instance of IExtractionResult interface containing the extraction results.
IExtractionResult extractionResult = htmlExtractor.Extract(source);
- To convert the extraction result to JSON string, use the ToJsonString method of the IExtractionResult interface.
Console.Write(extractionResult.ToJsonString());
Consider the following source confirmation email from which you want to extract the text using the HTML extractor we have configured above:
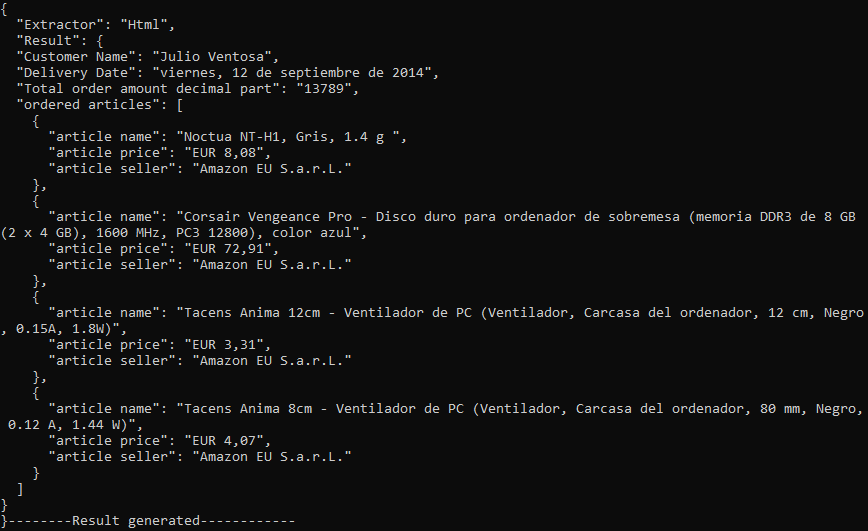
Following image shows the parsed result in JSON string format: